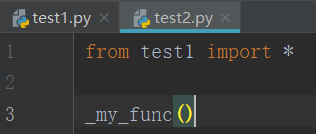
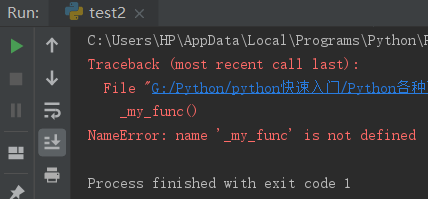
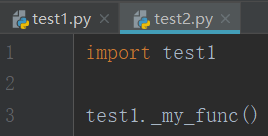
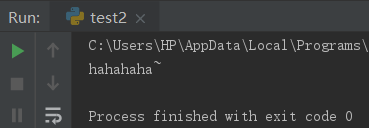
多线程和多进程理解
线程:threading
进程:processing
1、threading 更多的是使用在频繁 I/O 的并发场景中,
玩过爬虫的都知道,
我们有时候会通过爬虫下载网页上的图片或其它文件内容,
这时候我们就可以使用 Python 的 threading 模块来做到多线程执行。
2、processing 更多的是针对要充分使用 CPU 的并行场景,
比如的电脑的 CPU 是六核,
你希望你的程序运行能充分利用到六核,
那么就可以使用 processing。
开户 1 个线程去执行 2 的 10 次方
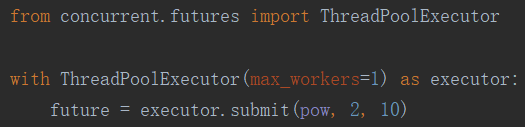
再来看一个爬虫例子
不使用多线程的情况:
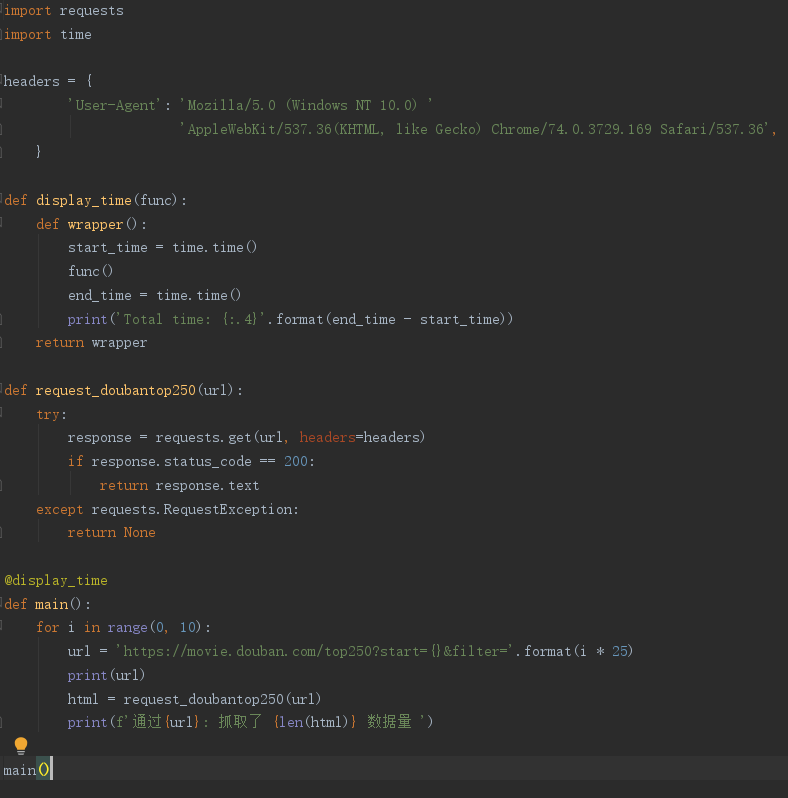
可以看到总耗时2.9+秒完成爬取
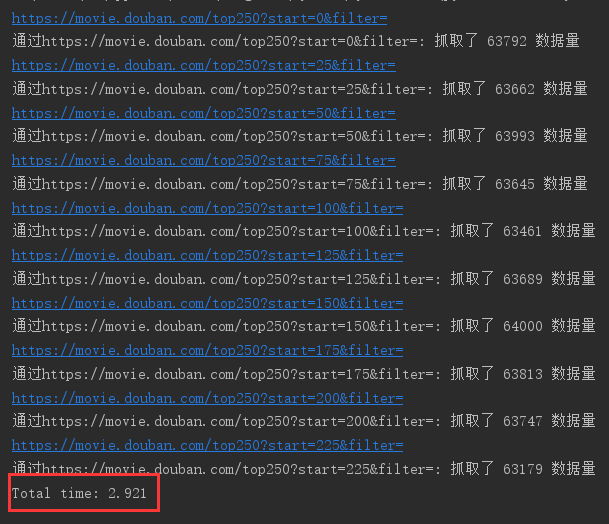
再来看看开启多线程的情况
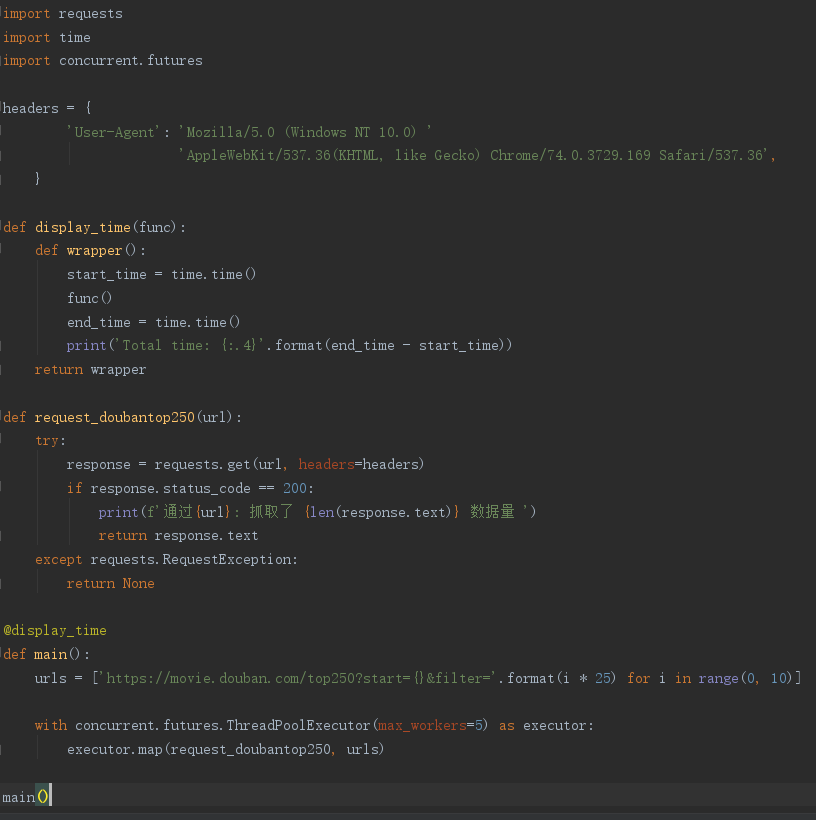
实现同样的功能,开启多线程只需0.8223秒就完成了
速度提高了 3.5+ 倍
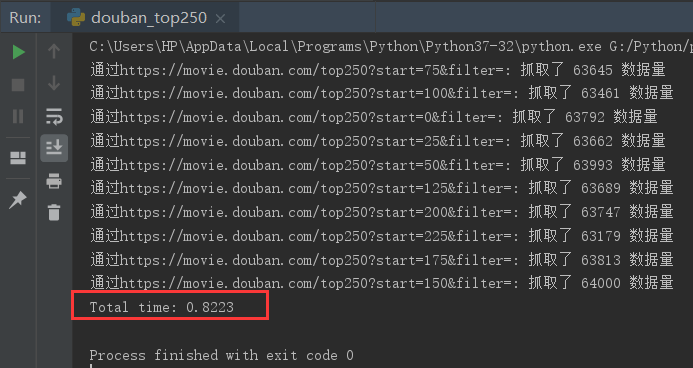
再来看看开启多进程,
把 ThreadPoolExecutor 改成 ProcessPoolExecutor 就可以了

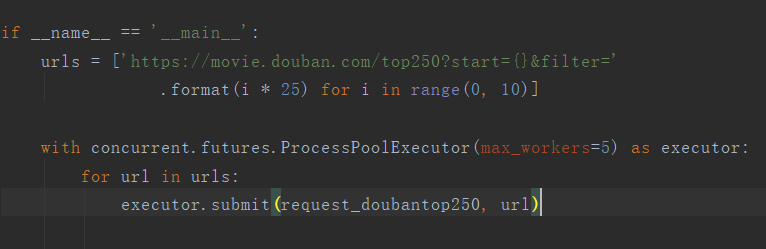
这里有个问题
多进程情况下,必要要用
if __name__ == ‘__main__:’
的方式才能运行多进程,否则报错
多线程不存在这个情况
这样能运行:
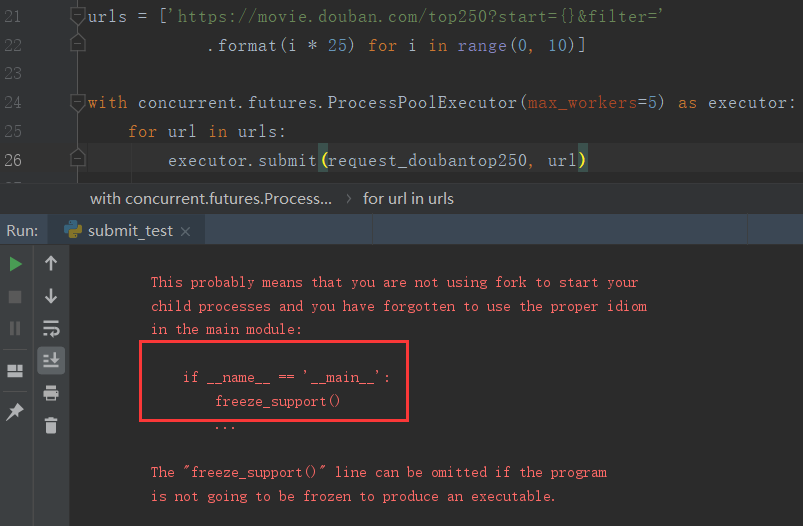
不加 if __name__ == ‘__main__:’ 报错:
提示要加 if __name__ == ‘__main__:’
理解 submit 和 map 两种方式
submit 方法:

map 方法:

它们的区别是:
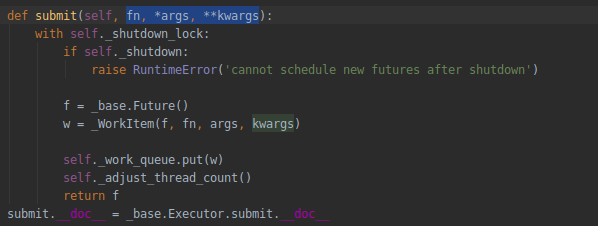
submit方法 是传入参数从而调用具体方法
源码:
map方法 是传入可迭代对象从而调用具体方法
源码:

多线程和多进程怎么选择的问题
CPU密集型:
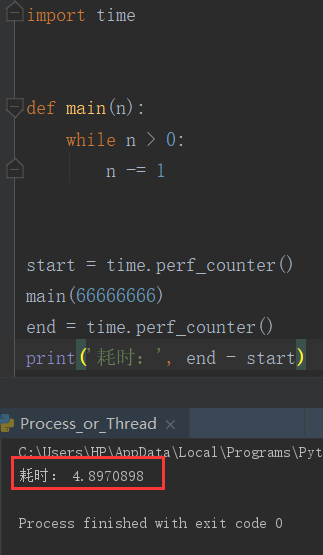
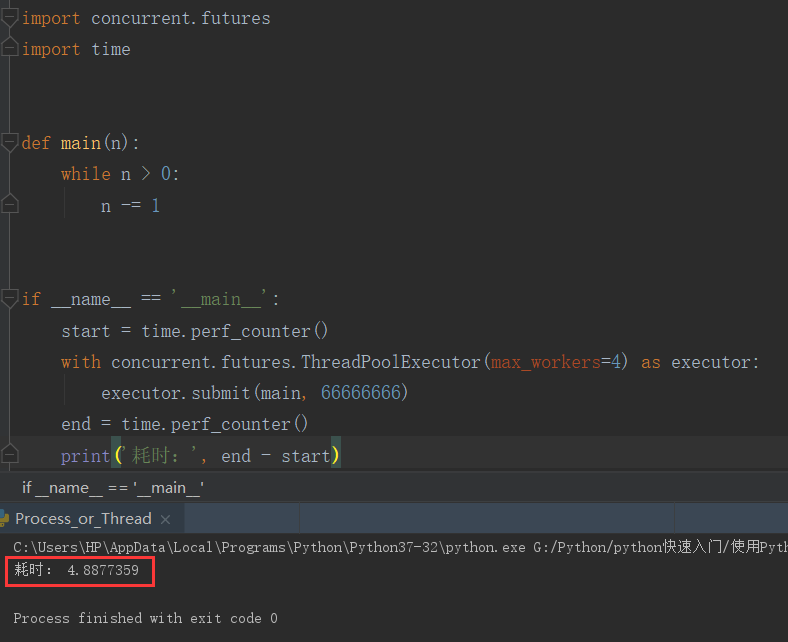
可以看到,多线程下执行时间并未缩短,单线程与多线程执行时间基本相同,这是由于GIL会把线程锁住,只允许一个线程执行
实际情况就是多线程至始至终还是单线程执行
- IO密集型:爬虫等频繁进行 IO 操作使用多线程较好,GIL会在IO等待时间里执行其它线程
- CPU密集型:对于主要是计算任务的CPU密集型程序使用多进程较好